




Magda Osman, Ph.D., Queen Mary University of London. This email address is being protected from spambots. You need JavaScript enabled to view it.. Biological and Experimental Psychology, School of Biological and Chemical Sciences, Queen Mary University of London, Mile End Road, London, E1 4NS, UK Telephone: +44 (0) 207 882 5903.
Alexandros Ananiadis-Basias, Research Assistant, Queen Mary University of London, Mile End Road, London, E1 4NS, UK.
Abstract
Perception, judgment, and reasoning are all processes that are sensitive to cues to animacy (i.e. the presence of signals that indicate an object behaves as if it has intentions and internal goals). The present study investigated the following question: Does animacy facilitate decision-making in a dynamic control system? To address this, the present study used a dynamic decision-making task and compared behavior in four different contexts (Abstract, Animate-Social, Inanimate-Social, InanimateNon-social). Participants were randomly allocated to one of these contexts, and in each version they were required to learn to manipulate variables in order to bring the dynamic system to a desirable state and maintain it at that level. The findings suggest that it is not animacy per se that facilitates decision-making behavior, but rather the presence of a context. However, animacy made an impact on the type of strategic behavior implemented when interacting with the dynamic system. We argue that context induces general beliefs about causal relationships in dynamic environments that generalize across animate as well as inanimate contexts.
Keywords: animacy, dynamic decision making, context, causality.
Introduction
There are a host of cognitive functions that suggest that we are highly sensitive to cues that imply animacy. As well as spatial and temporal features, one of the most reliable cues to infer animacy is whether or not an object behaves in a dynamic manner (Falmier & Young, 2008; Scholl & Tremoulet, 2000). That is to say, if the object moves in a co-ordinated way that we recognize as purposeful, then we are likely to infer that it is animate. What this means is that objects that display actions implying intentionality, and can therefore be interpreted as goal directed, are in turn highly salient to us (Goa, Newman, & Scholl, 2009). Some scientists have even suggested that the reason for this apparent bias is because we have “social brain” (Adophs, 2003; Gobbini, Koralek, Bryan, Montgomery, & Haxby, 2007) which is highly tuned to particular properties in the environment that display social-causal interactions. In fact, social contexts help consolidate complex information for the same reason that animacy does, and this is because these types of contexts can be interpreted as goal directed situations (Shafto, Goodman & Frank, 2011). Therefore, there are many arguments for suggesting that animacy is an important feature of objects which may even facilitate basic cognitive functions.
Perception studies suggest that we infer animacy in the movements of geometric objects (e.g. circle A moving in the same path as circle B), because the movements imply causal interactions that have a social element (e.g. circle A “chasing” another circle B) (Gao, Newman, & Scholl, 2009; Schlottmann, Ray, Mitchell, & Demetriou, 2006). As well as perception, studies examining memory retrieval (Fernandes, & Moscovitch, 2002; Traxler, Williams, Blozis, & Morris, 2005) and lexical decision-making (for some languages) (Gennari, Mirković, & MacDonald, 2012; Mak, Vonk, & Schriefers, 2002) show that if the stimuli are judged to be animate (i.e. living vs. non-living things) then they facilitate performance. In addition, investigations of causal reasoning have explored the facilitative effects of animacy on induction in children (Frankenhuis, House, Barrett, & Johnson, 2013) and adults (Zhou, Huang, Jin, Liang, Shui, & Shen, 2012). These studies also suggest that there is a reliable improvement in accuracy when inferences are made based on the presentation of stimuli that imply animacy.
Clearly, there is strong support for a view that the perceived animacy of objects has a facilitative effect on various cognitive processes (Scholl & Tremoulet, 2000). More specifically, a stronger inference may be that cues to animacy play an important role in our cognition because they carry valuable causal information about the relational properties between objects we observe in the world (Falmier & Young, 2008). If we can understand the causal relationship between objects, this in turn would be useful when it comes to predicting and controlling objects in the world (Osman, 2010). One area in which this issue is particularly salient is in complex dynamic control situations. Researchers that are concerned with these contexts have focused on the kinds of decision making processes that are required to interact with and control outcomes in them (i.e. Dynamic Decision Making research).
Dynamic decision making
Dynamic decision-making environments are microworlds that simulate real life situations in which a complex dynamic system can change as a direct result of an individual’s actions upon it, a change can occur independently of the individual’s actions (i.e. autonomously) or as a result of a combination of the two, (e.g. a pilot flying an aircraft). More to the point, dynamic decisionmaking (DDM) is the process by which people manipulate input variables in such a way as to reach and maintain a desirable change in an output variable. Crucially, the underlying relationship between inputs and outputs in the system that the decision-maker interacts with is dynamic (Osman, 2010). For instance, take a simple context such as changing the value on the thermostat of your radiator to maintain a warm temperature in your living room. The room may warm up more or less quickly depending on how old the heating system is, and where in the world you are (e.g., winter in Finland), as a result you might be required to regulate (i.e. control) the value on the thermostat as times goes on. Typically, in DDM tasks participants start with a context (e.g., heating the home) and are then given a goal (e.g., learn to regulate the temperature of the sitting room to 18 degrees). They are then tested on their ability to adapt their knowledge to new goals (e.g., regulate the temperature to 12 degrees).
For many, the appeal of this research domain is because of its high validity, because many real world decision-making problems are dynamic and complex (e.g., Berry & Broadbent, 1984; Mathews, Tall, Lane, & Sun, 2011; Osman, 2010; Selten, Pittnauer, & Hohnisch, 2011). The contexts used in this research field range from controlling a water purification plant (Burns & Vollemeyer, 2002), an ecosystem (Vollemeyer, Burns & Holyoak, 1997), water pump (Gonzalez, 2005), sugar factory (Berry & Broadbent, 1984), military management (Mathews et al, 2011), to a patient’s health (Osman & Speekenbrink, 2012). However, to the authors’ knowledge, there have been no dedicated studies that have compared decision-making behavior across different contexts, in order to uncover the types of contexts that would facilitate decision-making behavior in complex dynamic systems.
Moreover, it may in fact be the case that the animacy of the system is a key factor that facilitates DDM. If the system is perceived as animate, then people may infer that the system is goal- directed, and therefore, this may facilitate causal reasoning that in turn leads to improved DDM (Hagmayer, Meder, Osman, Mangold, & Lagnado, 2010). Furthermore, examining the impact of the animacy on decision-making has practical implications. If a complex dynamic system is perceived to be animate, and in turn it is shown to facilitate DDM, then automated control systems could be couched more obviously in ways that could invoke perceptions of animacy.
Present study
Given that there is convergence across many different areas of cognitive research in suggesting a special status for animacy in cognition, we predict that decision-making performance should be more accurate for animate compared to inanimate dynamic systems. If the effect of animacy is strong, then we might expect an advantage in decision-making performance when compared with Inanimate contexts (Social, and Non-social). Therefore in the present study, we compared DDM performance in an Animate-Social Context, with an Inanimate-Social Context, Inanimate-Non-Social Context, and a baseline No Context version of our DDM task.
Methods
Participants: Eighty-eight graduate and undergraduate students from University College London and Queen Mary University of London volunteered to participate in the experiment for reimbursement of £6 ($9.18) (Mean age 23, SD 7.5). There were four conditions: Abstract [baseline] (n =22, F = 15), Animate-Social (n = 22, F = 10), Inanimate-Social (n =22, F = 16), InanimateNon-social (n=22, F= 12). All participants were tested individually. For each condition, participants were randomly allocated, so that half performed tests in the test phase in the order of Control Test 1 then Control Test 2, and the remaining half performed Control Test 2 first, then Control Test 1.
Design: The study included four different contexts (Abstract, AnimateSocial, Inanimate-Social, Inanimate-Non-social). But with this exception, all other aspects of the task were identical in all four conditions. We chose a non-linear system to examine participants’ ability to make decisions in this task. Our rational was that if non-linear tasks are difficult to perform (Lipshitz & Strauss, 1997) for the reason that the type of structure of the system is hard to learn, then facilitation via context should be easier to detect in measure of performance when compared to an abstract version of the task. The structure of the task consisted of three inputs and one output (see Equation 1).
y(t+1) = 1/(1+exp(-1*(y(t) - 30 + 6*|6 - x1(t)| + 5*|4 - x2(t)| + e(t)))
There were two inputs (x1, x2 as referred in the equation below) which had a direct effect on the output value when they were manipulated individually. The third input had no direct effect on the output (y(t)), hereafter referred to as Null input. In other words, a value selected by the participant for the third input had no direct consequence on the output value. Instead, the null input simply revealed the noise term in the equation (e (t)) below; the value of which was selected from a normal distribution with a zero mean and a standard deviation of 4. Participants were naïve to the underlying relationship between the inputs and the output, which can be described in the following equation, in which y (t+1) is the output value on the next trial. Each input parameter ranged from 0-10. The system was designed in such a way that in order to successfully manage the state of the system to the specific target goal, the optimal manipulation of the inputs required that for Input 1 values should be selected from a range between 4 and 8, and for Input 2, values from a range between 3 and 7 should be selected.
The general instruction to participants was that they would have a chance to play a game on the computer in which they had to learn to control a system by deciding what things to change from trial to trial. They were also informed that they would later be tested on their ability to control the system after they became familiar with it. Figure 1 presents screenshots of a typical trial as experienced by a participant in the Inanimate-Social version (the picture in the top right of each screen shot differed according to what condition participants were in). The task was performed on a desktop computer, using custom software written in C# for the .NET framework. The task consisted of a total of 172 trials, divided into two phases. The learning phase involved 60 learning trials and the test phase included two control tests each 40 trials long, and two prediction tests each of which waw 16 trials long. During learning participants were required to achieve and maintain a target value consistently across all 60 trials, and in each control test participants were presented with a target value to reach and maintain throughout the course of each test.
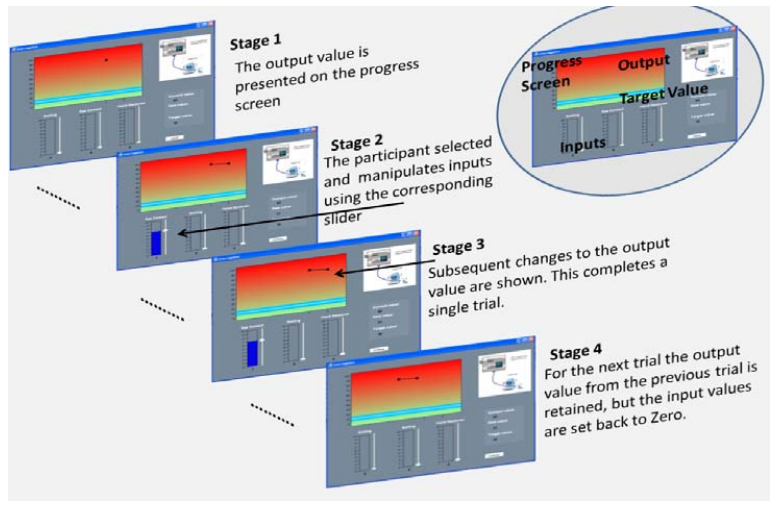
Materials: Abstract (Baseline version): The cover story for the abstract version did not contain any context. The inputs were simply labelled as A (i.e. Input 1) (0-10), B (i.e. Input 2) (0-10), and C (i.e. Input 3) (0-10), and the output was referred to as variable X (0-100). Participants were instructed to manipulate the inputs in order to control the output value to a specific level. Animate-Social Context: The cover story was set within a forensic context. Participants were told to imagine they were part of a forensic team, and that they had to interact with a policeman (animate) by varying three types of non-verbal behavior: Hand Gestures (i.e. Input 1) (Hand) – the amount of hand gesturing ranged from 0 (no hand gesturing) to 10 (constant hand gesturing), Eye Contact (i.e. Input 2) (Eye) – the amount of eye contact ranged from 0 (no eye contact) to 10 (constant eye contact), Smiling (i.e. Input 3) (Smile) – the amount of smiling ranged from 0 (no smiling) to 10 (constant smiling). Based on the data that the policeman received (i.e. the levels of Eye Contact, Smiling, and Hand Gestures on each trial) they would then give a rating of suspiciousness, which would be presented as a Suspicion value on the progress screen (i.e. Output value). Inanimate-Social Context: The cover story was identical to the Animate-Social version with one important exception. Instead of a policeman, participants were told that a lie detector machine processed the data on each trial. Thus, in this version the social context was retained since the variables that participants were manipulating (e.g., Hand gestures, Smiling, Eye-contact) are associated with social exchanges with other animate objects, but crucially participants were interacting with an inanimate object (i.e. lie detector). Inanimate-Non-Social Context: The cover story instructed participants to imagine they were engineers testing the effectiveness of a new oven on the market. The three inputs referred to components of the oven (Fan Speed (i.e. Input 1) – the fan speed ranged from 0 (not activated) to 10 (constantly operating), Vapor Pressure (i.e. Input 2) – the Vapour Pressure ranged from 0 (no Vapor Pressure) to 10 (constant Vapour Pressure), and Amplitude (i.e. Input 3) – the Amplitude ranged from 0 (no Amplitude) to 10 (constant Amplitude). Participants were also told that each of the three variables they could manipulate may have an effect on the temperature level of the oven. The framing of this context was designed to remove any social behaviors, and so participants were simply interacting with an inanimate object.
Procedure: Learning Phase: To begin, during learning participants were presented with a computer display with three inputs and one output (See Figure 1, top right panel). In all four conditions for trial 1 only the starting values of the inputs were set to 0, and the starting value of the output was pre-set to 80, while the target value for all 60 trials was 10. In all other trials the output value was not pre-set. Thus, the goal for each condition was the same, participants were required to reach and maintain the value 10 on each trial, which was depicted on a scale from 0-100 on a progress screen and also as a numerical value. At the start of the experiment it was made clear to participants that they were free to manipulate whichever combination of inputs they liked, or if they preferred, they need not necessarily manipulate any inputs on a trial. Once they were satisfied with their decision on a trial, they pressed a button to move on to the next trial (see Figure 1). The history of the output values generated across five consecutive trial periods remained on the progress screen while participants were interacting with the system. However, the trial history was a moving window of 5 trials long and so the progress screen was updated on each trial.
Test Phase: This phase was identical to the learning phase in all respect, with the following exception. Each control test was 40 trials long. In addition, in Control test 1 the starting value was 80 and participants were required to control the output value to 10 (i.e. the same as the target value during learning), and in Control test 2 the starting value was 10 and the target value was 85. Hence Control Test 2 was a test of transfer of knowledge. There were two tests of prediction, one presented after each control test. Here participants were given the values of inputs for a trial and then asked to predict the value of the output, or were given the value of the output on a trial, and were asked to predict the value of one of the inputs. For both Predictive Test 1 or Predictive Test 2 there were 16 trials, 4 trials to predict each of the following, Input 1, Input 2, Input 3 and the output. While values for Input 3 could not be entered into analysis (because the Input was a null variable), they were still presented in the prediction tests so as not to alert participants that there was anything peculiar about this input. The presentation of the 16 trials in each prediction test was randomized for each participant. No feedback was presented as to accuracy of performance in these tests.
Scoring: Control performance during the learning phase and the control test phase was calculated to generate an error score; this was the absolute difference between the achieved output on a trial and the target value. Thus a lower error score indicated better control of the system. InputManipulation: We used Osman and Speekenbrink’s (2011) simple method for identifying strategies. The Input- Manipulation method was based on calculating, for each participant, the proportion of trials across all 60 learning trials (or 40 trials each, per Control test) in which no input was changed (NoManipulation), one input was changed (One-Input) two inputs were changed (Two-Inputs), and all inputs cues were changed (All-Inputs). For scoring of predictive performance in the Predictive tests error scores were calculated; this was based on the difference between the predicted value and the actual value. Again, a lower error value indicated better predictive accuracy.
Results
This section is organized in accordance with the two phases of the experiment: Learning phase in which control performance and input manipulation were examined; Test phase in which control performance, input manipulation and predictive performance were analysed.
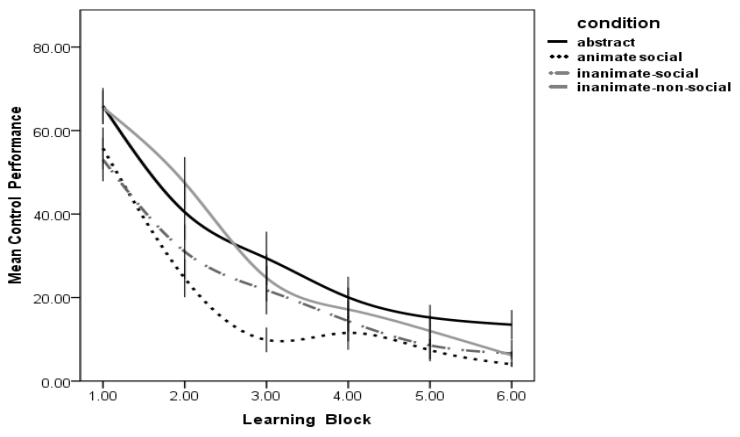
Learning Phase: The following analysis compared control performance during learning of all four conditions (Abstract, Animate-Social, InanimateSocial, Inanimate-Non-social). A 6 (Block) x 4 (Condition) repeated measures ANOVA was conducted, and it revealed that familiarity with the task increased performance significantly (see Figure 2), in a main effect of block F(5, 420) = 3.34, p = .006, partial η² = .03. Post-hoc comparisons revealed that there were significant differences in control performance between each block (t(87) > 2.5, p < .05), suggesting that control performance was incrementally improving across blocks. Planned comparisons also revealed that the AnimateSocial condition showed greater accuracy when controlling the output than the Abstract condition (t(42) = 2.40, p = .02), the Inanimate-Social condition showed a marginal significant difference in accuracy of control over the Abstract condition (t(42) = 1.79, p = .08), and Inanimate-Non-social condition also showed a significant advantage over the Abstract condition in control accuracy (t(42) = 2.13, p = .03). No other comparisons were significant. The findings suggest that learning to control a system without a context impairs performance as compared to when a context is present.
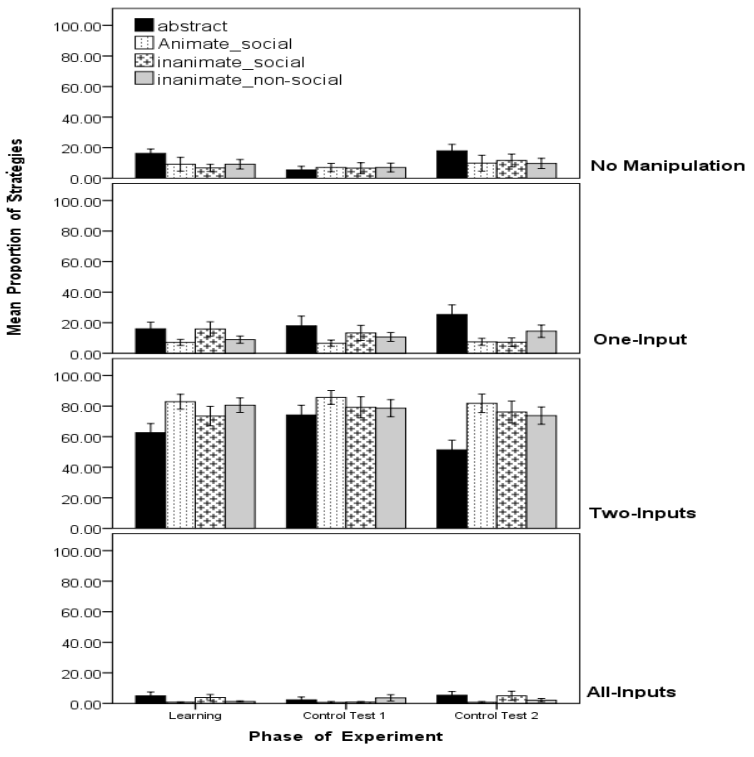
We also conducted a 4x4 ANOVA using Input-manipulation (NoManipulation, One Input, Two Inputs, All inputs) as within-subject factors, and Condition (Abstract, Animate-Social, Inanimate-Social, Inanimate-Non-social) as the between-subject factor. There was a main effect of Input-manipulation method, F(3,252) = 256.39, p = 0.0006, partial η² = .73, indicating that people used the four types of input manipulations to different degrees. With the exception of comparisons between No-Manipulation and One-Input, all other comparisons between types of Input manipulations were significant, with Bonferroni correction (t(87), p < 0.001) (See Figure 3). The analysis also revealed the following interactions. There was an Input-manipulation method x Condition interaction, F(9,252) = 2.22, p = 0.02, partial η² = 0.07. Follow up analyses revealed that those in the Abstract condition employed the TwoInput strategy less than the Animate-Social (p < 0.05), and the InanimateNon-Social, (p < 0.05). No other analyses were significant.
Testing phase: A 2 (Test) x 4 (Condition) x 2 (Control Test order 1 & 2) ANOVA was conducted on test performance scores. The analysis showed there was a significant effect of condition, F(1,84) =5.07, p = .003, partial η² = .15. Planned comparisons revealed that the Animate-Social condition (Mean = 13.19, SD = 8.53) was more accurate at controlling the output than the Abstract condition (Mean = 19.71, SD = 13.90) (t(42) = 4.20, p = .0001). Also, the Inanimate-Social condition (Mean = 14.03, SD = 9.38) showed a significant advantage over the Abstract condition (t(42) = 2.92, p = .005), and InanimateNon-social condition (Mean = 15.61, SD = 12.90) also showed a significant advantage over the Abstract condition in control accuracy (t(42) = 2.47, p = .01). No other comparisons were significant. Again, consistent with the pattern of results in learning phase, in the test phase control performance was facilitated by the presence of a context.
We conducted a 2x4x4 ANOVA using Test (Control Test 1, Control Test 2, and Input-manipulation method (No-Manipulation, One Input, Two Inputs, All Inputs) as within-subject factors, and Condition (Abstract, Animate-Social, Inanimate-Social, Inanimate-Non-social) as the between-subject factor. There was no significant difference in the pattern of Input manipulations in Control Test 1 and Control Test 2, so we collapsed across tests (F<1). There was a main effect of Input-manipulation method, F(3,252) = 239.10, p = 0.0002, partial η² = .74. As with the learning phase, here too with the exception of comparisons between No-Manipulation and One-Input, all other comparisons between types of Input manipulations were significant, with Bonferroni correction (t(87), p < 0.001) (see Figure 3). The analysis also revealed the following interactions. There was an Input-manipulation method x Condition interaction, F(9,252) = 2.13, p = 0.02, partial η² = 0.07. Follow up analyses revealed that those participants in the Abstract condition employed the Two-Input strategy less than the Animate-Social, (p < 0.05). In addition, those in the Abstract condition utilized the One-Input strategy more than the Animate-Social. No other analyses were significant.
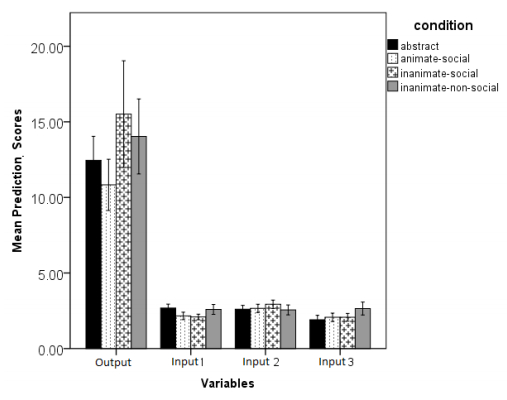
After the main experiment participants were required to predict the value of each of the three inputs, and the output. However, our analyses concern the prediction scores for Input 1 and Input 2 and the Output value. We omitted Input 3 from the analyses because it was a null input. A 2 (Input 1, Input 2, Output) x 2 (Prediction Test 1, Prediction Test 2) x 4 (Abstract, Animate-Social, Inanimate- Social, Inanimate-Non-social) ANOVA was conducted. The analyses revealed a main effect of input (see Figure 4), suggesting that overall, accuracy in predicting the values of the two input variables and the output variable differed, F(1,84) = 148.17, p = .0003, partial η² = .65. No other analysis was of significance. Given that there was no difference between scores for Prediction Test 1 and Prediction Test 2, they were combined in order to perform post-tests. The analyses revealed that prediction judgments for the output value were significantly more inaccurate as compared to predictions for Input 1 t(87) = -8.96, p = .0005, and compared with Input 2 t(87) = -8.65, p = .0003. In addition, predictions were more inaccurate for Input 2 as compared to Input 1, t(87) = -2.06, p = .04. No other analysis achieved the significance level.
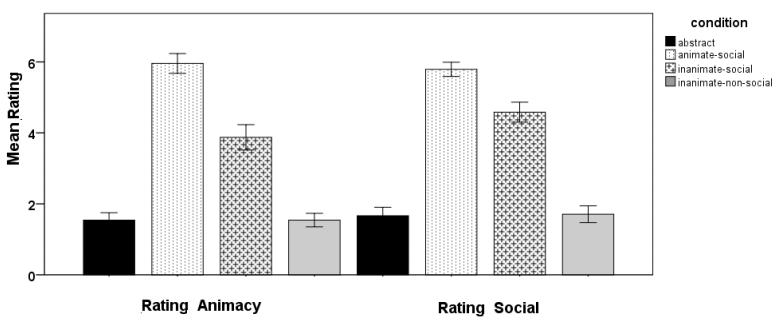
Manipulation Check: The manipulation check was used to examine if the four contexts were differentiated on the basis of animacy and social context. An additional set of 24 undergraduate and postgraduate volunteers (mean age 28.0, SD = 4.8) from Queen Mary University of London were presented with just the cover stories for each of the four conditions (Abstract, AnimateSocial, Inanimate-Social, Inanimate-Non-social). The presentation of the cover stories was randomized for each participant. At the end of reading each cover story, participants were required to rate the animacy of the object to be controlled (i.e. Animate-Social= Policeman’s mental state, InanimateSocial = Lie-detector, Inanimate-Non-social = Cooker, Abstract = Unspecified). They responded on a scale from 1 “definitely not alive” to 7 “definitely alive” (Tremoulet & Feldman, 2000). Participants also had to rate whether an interaction with the system was social, by which we meant that the cover story required that people considered their interactions to primarily involve a human agent. They responded on a scale from 1 “not at all social” to 7 “definitely social”. The mean responses to both questions are presented in Figure 5. We submitted the ratings into an ANOVA with 2 (Rating of Animacy, Rating of Sociality) x 4 (Abstract, Animate-Social, Inanimate-Social, InanimateNon-social) ANOVA being conducted. There was a significant main effect of condition, F(2,69) = 138.75, p = .0003, partial η² = .85. There was no significant difference in the pattern of responses between the two types of ratings. With the exception of comparisons between Abstract and Inanimate-Non-social, all paired t-test comparisons were significantly different in ratings for Animacy as indicated in Figure 5 (p < .001). Similarly, for ratings for Sociality, there was no difference between Abstract and Inanimate-Non-social contexts, whereas all other comparisons were significant (p< .005).
Discussion
The present study sought to investigate the faciliatory effects of animacy on dynamic decision-making. The second objective of this study was to compare decision making performance across different contexts in the same nonlinear system. To this end, the study revealed a robust context effect that was preserved across both learning and test phases of the experiment.
In summary, having measured control performance we found no evidence to suggest that animacy per se facilitated performance, however, the findings clearly showed that in learning and in test contextualized versions of the DDM task facilitated performance. In addition, strategic behavior during learning and test indicated that those in the Abstract condition (without context) manipulated fewer combinations of inputs than those in contextualized conditions, particularly the Animate- Social condition. This suggests that animacy impacted on the type of strategy that participants implemented. However, when measuring predictive accuracy, the findings of this study suggest that this was insensitive to the context and animacy manipulations. Participants were more accurate when predicting cause to effect (i.e. input value, given an output value) then predicting effect to cause (i.e. output value, given input values). A prosaic explanation for this pattern of results may be that the range of values for the inputs was between 0-10, and so the scope for error was smaller than for estimating the output value, which could range from 0-100. In the remainder of this discussion we consider two questions.
In dynamic decision-making tasks why might animacy effect performance less than context? To begin, we are confident, based on our manipulation checks, the cover stories were distinguishable on the basis of animacy and sociality, and they led in the direction we expected. Therefore, we would expect that in the main study participants were initially sensitive to the type of context they were in, at least with respect to reading the cover story and the instructions. However, it may be the case that when it then came to interacting with the system, over time other more general factors became more salient than the animacy of the system. In other words, the presence of a context that could invoke general prior knowledge could be utilized more effectively than any specialized knowledge concerning the animacy of the objective being controlled. There is good evidence to suggest that people recruit prior experiential knowledge in order to perform complex decision making and problem solving tasks (Lane, Mathews, Sallas, Prattini, & Sun, 2008; Mathews et al, 2011).
This type of knowledge may include general causal beliefs about how components of a system interact with each other (Bechlivanidis & Lagnado, in press). In addition, it may well be the case that this type of knowledge is likely to be more effective, given that the specific causal relationships between inputs and outputs in the systems used in the present study were artificial. We constructed a system in which performance could legitimately be compared across all four contexts we devised, which was necessary for the purposes of this study. As a consequence, prior knowledge about the types of relations referred to in the animate context used in the present study was unlikely to be applicable to solving the task, as compared to a general understanding about the way in which inputs and outputs may behave in contexts that contain non-linear relationships. However, with respect to this point, the findings do suggest that there was a specific and consistent difference, both in learning and test, between the Animate-Social and the Abstract contexts. Here we speculate that people may have more prior experience of non-linear relationships in animate than inanimate contexts, and as a result people are more interactive with non-linear systems, which may explain why participants showed a consistent tendency to manipulate more inputs than when there is no context present. Putting it another way, the general reluctance to manipulate multiple inputs at a time in the abstract context may reveal that participants were more tentative and perhaps more conservative in their approach to the system.
Why does context matter in dynamic decision-making tasks? One reason may in fact be that contexts facilitate the intake of causal knowledge, and so there is a deeper issue concerning how people interact with DDM tasks which facilitate causal knowledge. Controlling a dynamic environment requires intervention-based decisions, which involves planning the choice of which input to manipulate and estimating the likely output from that intervention (Hagmayer, et al, 2010; Rottman, & Keil, 2012). The role of causal knowledge in DDM research is only a recent research issue, but gaining in momentum (Hagmayer, et al, 2010; Hagmayer & Osman, 2012; Rottman, & Keil, 2012). These theorists converge on the view that people’s predictions and choice of actions in dynamic environments are founded on their causal knowledge of the relationships between inputs and outputs (Lagnado, Waldmann, Hagmayer, & Sloman, 2007; Glymour, 2003; Sloman, 2005). Therefore, the presence of a context facilitates the uptake of causal knowledge, which in the case of the present study is all the more impressive, given that participants were required to learn to control a dynamic non-linear system. However, it is also important to bear in mind that the relationship between context and the underlying causal structure of the system used in the present study was completely arbitrary. Despite the fact that great efforts were made to make the contexts themselves, any facilitation that did occur must have been based on participants associating their experience with manipulating the inputs to the available real world concept that the task provided, which the abstract condition did not offer. This association appeared to be so significantly strong that it impacted on the types of strategies that were developed to control the system. Given this implication, if participants are indeed sensitive to the context, then presumably DDM performance should suffer if the underlying causal system contradicts the context that the system is couched in. For instance, in a case where an input-output variable had a negative linear relationship, but the context implied a positive linear relationship (e.g., turning the bath tap, in order to fill the bath). Finally, a more general point that can be made here is that if context matters, then our ability to successfully control systems in the real world may be determined by how effectively we can utilize causal knowledge.
Conclusion
There are several compelling demonstrations of the facilitatory effects of cues to animacy (e.g., dynamics) on performance in a variety of cognitive processes; however this has not been explored in the context of dynamic decision-making. The present study was the first of its kind to directly compare decision-making performance in a non-linear dynamic system across a variety of contexts. The findings reveal that there was a general performance advantage when the system was couched in a context, regardless of whether or not it was animate. In addition, the pattern of strategic behavior in the system indicates that animacy encourages greater interaction than when the system is devoid of context. The present study proposes that the facilitatory effects of context in dynamic decision-making can be explained on the basis of general causal beliefs that people bring to bear to help them co-ordinate their actions in a dynamic system.
Acknowledgments
This study was supported by the Engineering and Physical Sciences Research Council, EPSRC grant – EP/F069421/1. We would also like to thank Maarten Speekenbrink for preparing the experimental program and for his careful and insightful comments.
References
- Bechlivanidis, C., & Lagnado, D. A. (in press). Does the “Why” Tell Us the “When”?. Psychological Science.
- Berry, D., & Broadbent, D. E. (1984). On the relationship between task performance and associated verbalizable knowledge. Quarterly Journal of Experimental Psychology: Human Experimental Psychology, 36, 209–231.
- Burns, B. D., & Vollmeyer, R. (2002). Goal specificity effects on hypothesis testing in problem solving. Quarterly Journal of Experimental Psychology, 55, 241–261.
- Falmier, O., & Young, M. E. (2008). The impact of object animacy on the appraisal of causality. The American Journal of Psychology, 121, 473-500.
- Fernandes, M. A., & Moscovitch, M. (2002). Factors modulating the effect of divided attention during retrieval of words. Memory & Cognition, 30, 731-744.
- Frankenhuis, W. E., House, B., Barrett, C, H., & Johnson, S. P. (2013). Infants’ perception of chasing. Cognition, 126, 224–233.
- Gao, T., Newman, G. E., & Scholl, B. J. (2009). The psychophysics of chasing: A case study in the perception of animacy. Cognitive Psychology, 59, 154-179.
- Gennari, S. P., Mirković, J., & MacDonald, M. C. (2012). Animacy and competition in relative clause production: A cross-linguistic investigation. Cognitive Psychology, 65, 141-176.
- Gonzales, C. (2005). Decision support for real-time, dynamic decision-making tasks. Organizational Behavior and Human Decision Processes, 96, 142–154.
- Glymour, C. (2003). Learning, prediction and causal Bayes nets. Trends in Cognitive Sciences, 7(1), 43-48.
- Hagmayer, Y, Meder, B, Osman, M, Mangold, S., & Lagnado, D. (2010). Spontaneous Causal Learning While Controlling A Dynamic System. The Open Psychology Journal, 3, 145-162.
- Hartwig, M., Granhag, P. A., Strömwall, L. A., & Andersson, L. O. (2004). Suspicious minds: Criminals’ ability to detect deception. Psychology, Crime and Law, 10(1), 83-95.
- Lane, S. M., Mathews, R. C., Sallas, B., Prattini, R., & Sun, R. (2008). Facilitative interactions of model- and experience-based processes: Implications for type and flexibility of representation. Memory & Cognition, 36, 157–169.
- Lagnado, D. A., Waldmann, M. R., Hagmayer, Y., & Sloman, S. A. (2007). Beyond covariation. Causal learning: Psychology, philosophy, and computation, 154-172.
- Lipshitz, R., & Strauss, O. (1997). Coping with uncertainty: A naturalistic decision-making analysis. Organizational Behavior and Human Decision Processes, 69, 149–163.
- Mak, W. M., Vonk, W., & Schriefers, H. (2002). The influence of animacy on relative clause processing. Journal of Memory and Language, 47, 50–68.
- Mathews, R. C., Tall, J., Lane, S. M., & Sun, R. (2011). Getting it right generally, but not precisely: learning the relation between multiple inputs and outputs. Memory & Cognition, 39, 1133-1145.
- Osman, M. (2008). Positive transfer and negative transfer/anti learning of problem-solving skills. Journal of Experimental Psychology: General, 137, 97–115.
- Osman, M. (2010). Controlling Uncertainty: Learning and Decision-making in complex worlds. Wiley-Blackwell Publishers, Oxford.
- Rottman, B. M., & Keil, F. C. (2012). Causal structure learning over time: observations and interventions. Cognitive Psychology, 64(1), 93-125.
- Scholl, B. J., & Tremoulet, P. (2000). Perceptual causality and animacy. Trends in Cognitive Sciences, 4, 299–309. Selten, R., Pittnauer, S., & Hohnisch, M. (2011). Dealing with Dynamic Decision Problems when Knowledge of the Environment Is Limited: An Approach Based on Goal Systems. Journal of Behavioral Decision-Making, 25, 443-457.
- Shafto, P., Goodman, N. D., & Frank, M. C. (2012). Learning From Others: The Consequences of Psychological Reasoning for Human Learning. Perspectives on Psychological Science, 7(4), 341-351.
- Sloman, S. (2005). Causal models: How people think about the world and its alternatives. Oxford University Press, USA.
- Traxler, M., Williams, R. S., Blozis, S. A., & Morris, R. K. (2005). Working memory, animacy, and verb class in the processing of relative clauses. Journal of Memory and Language, 53, 204-224.
- Tremoulet, P. D., & Feldman, J. (2000). Perception of animacy from the motion of a single object. Perception, 29, 943–951
- Vollmeyer, R., Burns, B. D., & Holyoak, K. J. (1996). The impact of goal specificity and systematicity of strategies on the acquisition of problem structure. Cognitive Science, 20, 75–100.
- Zhou, J., Huang, X., Jin, X., Liang, J., Shui, R., & Shen, M. (2012). Perceived causalities of physical events are influenced by social inputs. Journal of Experimental Psychology: Human Perception and Performance, 38, 1465-1475.